Install Windows XP
Most new computers come with Windows XP installed, so many people never have to install it. However, you may need to install Windows XP if:
| • | You replaced your hard disk drive with a new hard disk drive that does not have Windows XP installed. |
| • | You are reinstalling Windows XP on a computer because you want to clean off your hard drive and remove any unwanted programs, such as spyware. |
| • | You purchased a computer without an operating system. |
Fortunately, you do not need to be a computer expert to install Windows XP. Installing Windows XP is a straightforward process that takes between one to two hours. Of that time, you need to be present for only about 30 minutes.
| • | |
| • |
Note: If you have a computer with an older operating system, such as Windows 98, Windows ME, or Windows 2000, you should upgrade to Windows XP instead of performing a clean installation.
Pre-installation checklist
Before you begin the installation process, use this checklist to make sure that you are prepared:
You have the Windows XP CD.
You have the product key available. The product key is located on your Windows XP CD case and is required to install and activate Windows XP.
Your computer hardware is set up. At a minimum, you should connect your keyboard, mouse, monitor, and CD drive. If available, you should connect your computer to a wired network.
You have Windows XP drivers available. Drivers are software that Windows XP uses to communicate with your computer’s hardware. Most new computers include a CD containing drivers. If you do not have drivers available, Windows XP may already include drivers for your hardware. If not, you should be able to download them from your hardware manufacturer’s Web site after you set up Windows XP.
If you are reinstalling Windows XP on an existing computer, you need a backup copy of your files and settings. The installation process will delete all of your files. You can use the File and Settings Transfer Wizard to store your files and settings on removable media and then restore them after installation is complete.
Installation process
Installing Windows XP can take up to two hours. To make the process more manageable, it has been broken up into several sections. When you are ready, install Windows XP:

Part 1: Begin the installation
1. | Insert the Windows XP CD into your computer and restart your computer. |
2. | If prompted to start from the CD, press SPACEBAR. If you miss the prompt (it only appears for a few seconds), restart your computer to try again. |

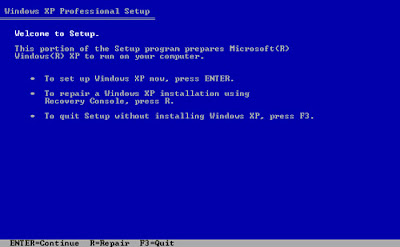
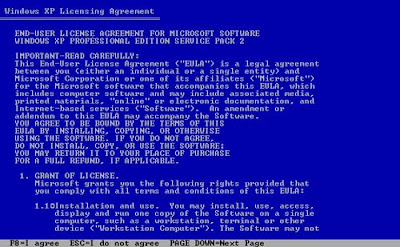
4. On the Windows XP Licensing Agreement page, read the licensing agreement. Press the PAGE DOWN key to scroll to the bottom of the agreement. Then press F8.




 · The RAG above is compose of 2 resources and 2 processes
· The RAG above is compose of 2 resources and 2 processes














{kind=link}
{kind=link}